Last month, Anthropic's Marina Favaro and Jack Clark published When AI builds itself, a measured look at how close AI has come to driving its own development.[1] The headline number is hard to ignore: Anthropic engineers now ship, on average, roughly eight times as much code per quarter as they did across 2021–2025. More than 80% of the company's merged production code is now written by Claude, up from single digits before February 2025. The report is careful not to declare victory — recursive self-improvement, it stresses, is “not inevitable” — but the curves it documents are steep, and they match what we have watched happen inside our own studio almost exactly.
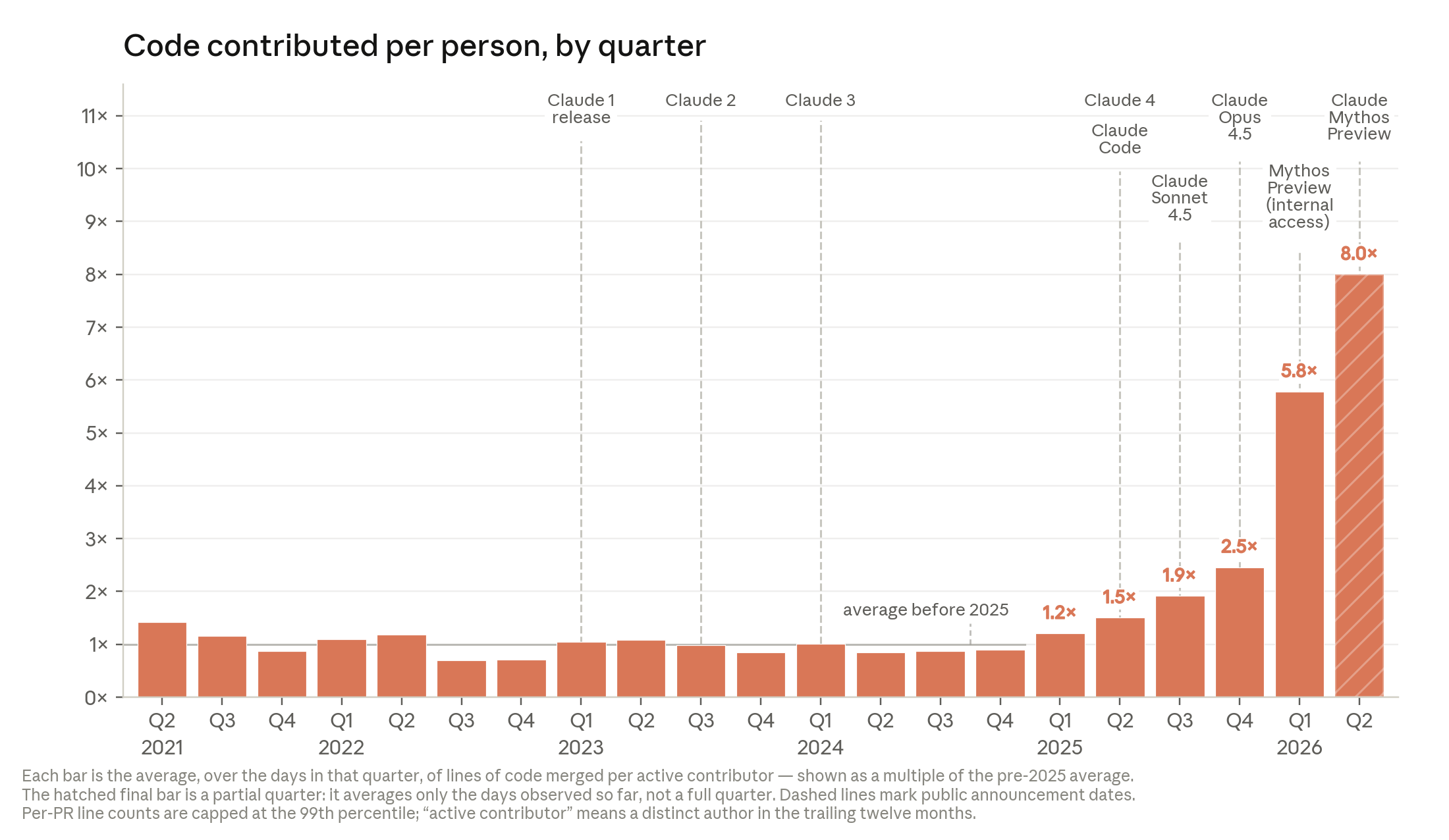
We are not a frontier lab. We are a small studio that builds websites, APIs, and AI integrations for real businesses. And yet the shape of Anthropic's first chart — flat through 2021–2024, then bending hard upward in 2025 — is the same shape we would draw from our own commit history. Since the start of 2025, the lines of code produced at Autonomous Agent AI have risen roughly tenfold. We did not hire ten times the engineers. We did not work ten times the hours. What changed was the tooling, and specifically the arrival of coding agents that can read a repository, plan a change, edit a dozen files, run the tests, and fix what broke — all in a single sitting.
The report breaks the last five years into stages: humans writing every line; chatbots offering snippets; agents editing files; and now agents that execute, verify, and delegate. We lived that progression on a compressed timeline. In 2024 we used Claude the way you would use a very fast pair programmer — paste a function, ask for a refactor, copy it back. By the beginning of 2026, something had flipped. Today, Claude writes about 95% of the code we ship. Our engineers spend their hours where the report says human judgment still rules: deciding what to build, setting the constraints, and deciding whether the result is actually any good.
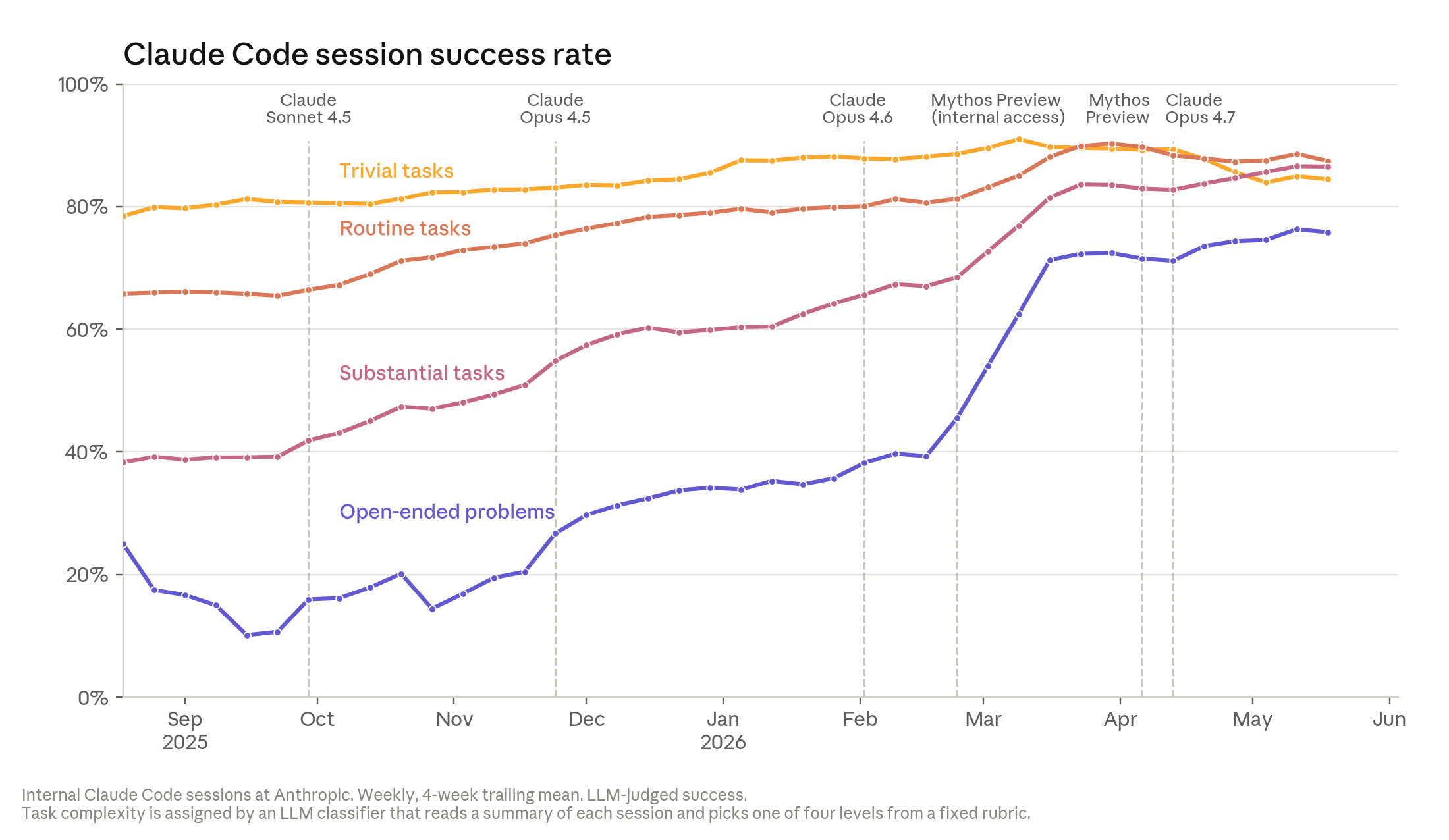
That last point deserves emphasis, because the most surprising part of our own experience is not speed — it is quality. The intuition most clients bring is that more machine-written code must mean more bugs. We have found the opposite. As our share of Claude-authored code climbed past 90%, the number of defects we encounter in production went down, not up. Anthropic's own data tells the same story: code that was “somewhat worse than human-written” in late 2025 is “roughly at parity today,” and the success rate on hard, open-ended sessions has marched steadily upward across a single year of model releases. A model that runs the test suite before it hands you the diff catches a whole class of mistakes that a tired human at 6 p.m. simply misses.
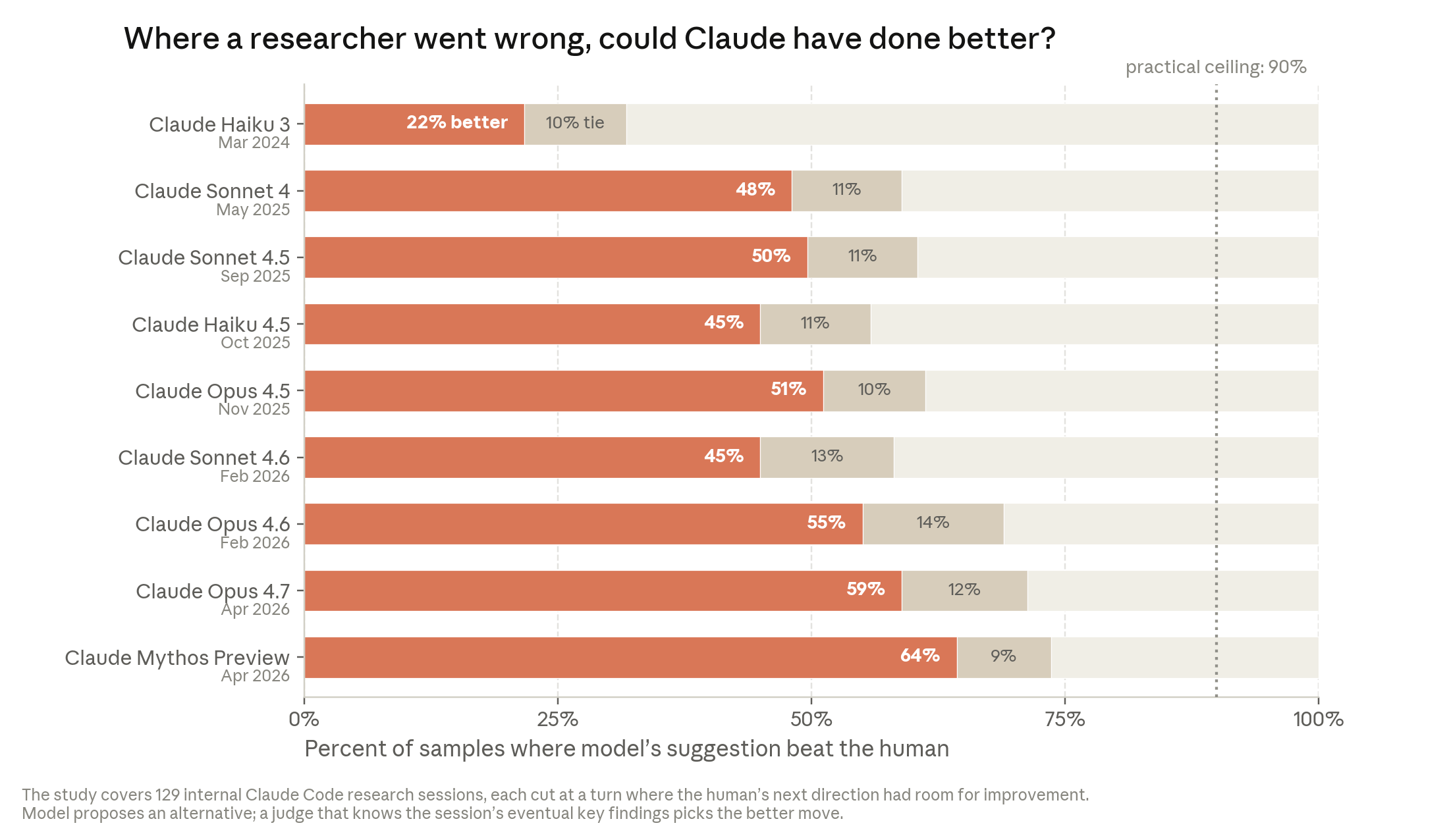
The third chart is the one that should make every studio owner sit up. It asks a pointed question — when a human researcher picked a direction that turned out to be wrong, could Claude have picked better? — and the answer has crept from 22% with an early model to 64% with the most recent preview. That is no longer a tool that merely types faster than you. It is a tool that, increasingly often, has better judgment about what to do next than the person holding it.
We want to be honest about the part of the report that is not a victory lap. Favaro and Clark spend their final pages on governance: the case for international coordination, for verification regimes, for keeping humans in the loop on the questions that matter most. They are explicit that a unilateral slowdown merely hands the lead to someone less cautious, and that the people who should be weighing in — policymakers, researchers, ordinary citizens — are mostly not in the room yet. We agree. The same compounding that turned our 10x into a 95% is the compounding that, taken to its end, removes the human from the loop entirely. The difference between a windfall and a hazard is whether we keep deciding what the windfall is for.
For now, our experience maps cleanly onto the optimistic-but-bounded middle scenario the report sketches: humans still set direction, AI handles execution, and output multiplies. We are living proof that a small shop can ship like one several times its size. We just think the chart should carry the same caveat Anthropic put on its own — the line is bending, and it is worth staying awake while it does.
References
- Favaro, M. and Clark, J. “When AI builds itself.” Anthropic. anthropic.com/institute/recursive-self-improvement↩